5. 控制冒险和分支预测
mips大约 5 分钟
目标
- 了解控制冒险与分支预测
- 了解动态分支预测
- 使用BTB优化程序
- 了解循环展开,对比BTB
内容
- 针对矩阵乘法的代码,开启BTB功能,观察流水线细节,分析BTB的功能
- 设计一段BTB脱敏的代码
- 使用循环展开,对比采用BTB。
- x86上编写c程序-矩阵乘法,使用perf观察分支预测失败次数。 验证次数。是否吻合。 继续编写令BTB失效的代码,验证x86能否正常预测,尝试做出解释。
矩阵乘法及其优化(开启BTB)
伪代码
for(int i = 0; i < 8; i ++) {
for(int j = 0; j < 8; j ++) {
int local_sum = 0;
for(int k = 0; k < 8; k ++) {
local_sum += mx1[i][k] * mx2[k][j];
}
mx3[i][j] = local_sum;
}
}MIPS
.data
str: .asciiz "the data of matrix 3:\n"
mx1: .space 512
mx2: .space 512
mx3: .space 512
.text
initial:
daddi r22, r0, mx1
daddi r23, r0, mx2
daddi r21, r0, mx3
input:
daddi r9, r0, 64
daddi r8, r0, 0
loop1:
dsll r11, r8, 3
dadd r10, r11, r22
dadd r11, r11, r23
daddi r12, r0, 2
daddi r13, r0, 3
sd r12, 0(r10)
sd r13, 0(r11)
daddi r8, r8, 1
slt r10, r8, r9
bne r10, r0, loop1
daddi r16, r0, 8
daddi r17, r0, 0
loop2:
daddi r18, r0, 0
loop3:
daddi r19, r0, 0
daddi r20, r0, 0
loop4:
dsll r8, r17, 6
dsll r9, r19, 3
dadd r8, r8, r9
dadd r8, r8, r22
ld r10, 0(r8)
dsll r8, r19, 6
dsll r9, r18, 3
dadd r8, r8, r9
dadd r8, r8, r23
ld r11, 0(r8)
dmul r13, r10, r11
dadd r20, r20, r13
daddi r19, r19, 1
slt r8, r19, r16
bne r8, r0, loop4
dsll r8, r17, 6
dsll r9, r18, 3
dadd r8, r8, r9
dadd r8, r8, r21
sd r20, 0(r8)
daddi r18, r18, 1
slt r8, r18, r16
bne r8, r0, loop3
daddi r17, r17, 1
slt r8, r17, r16
bne r8, r0, loop2
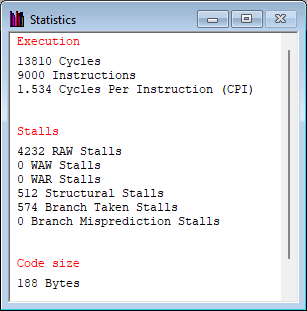
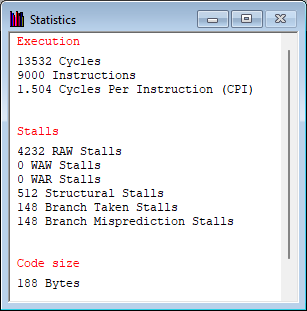
halt- 通过 Statistics 窗口观察 开启BTB前后 的统计数据。
提示
仅观察 Branch Taken Stalls 和 Branch Misprediction Stalls
截图
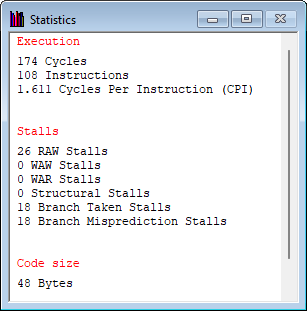
设计使BTB无效的代码
提示
利用特性:BTB的跳转判定 取决于之前跳转的成功与否。
示例
可以构造一个连续出现0和1的数组
遍历数组,以判定元素为0作为跳转条件,使得分支预测器总是无法正确预测下一个分支的方向。
伪代码
// 交替出现的 0 和 1
int array[] = {0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1};
int length = 16;
for (int i = 0; i < length; i++) {
if (array[i] != 0) continue;
}MIPS
.data
array: .word 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1
.text
daddi r23, r0, array # 数组的地址加载
daddi r9, r0, 16 # 数组长度
daddi r8, r0, 0 # 计数器r8
loop: dsll r11, r8, 3 # 根据计数器得到偏移量
dadd r10, r11, r23 # 数组元素地址
ld r12, 0(r10) # 取值
daddi r8, r8, 1 # 计数器自增
bne r12, r0, loop # 元素若不为0的判断
slt r10, r8, r9 # 计数器是否小于数组长度
bne r10, r0, loop # 没有越界就继续遍历
daddi r17, r0, 1 # 辅助(无意义)
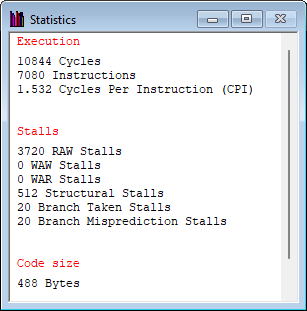
halt矩阵乘法的循环展开
在每次迭代种执行更多的数据操作来减小循环开销的影响。基本思想是把操作对象线性化,在一次迭代中访问线性数据中的一个组,从而减少迭代次数,降低循环开销。
循环展开
伪代码
for(int i = 0; i < 8; i++) {
for(int j = 0; j < 8; j++) {
int local_sum = 0;
local_sum += mx1[i][0] * mx2[0][j];
local_sum += mx1[i][1] * mx2[1][j];
local_sum += mx1[i][2] * mx2[2][j];
local_sum += mx1[i][3] * mx2[3][j];
local_sum += mx1[i][4] * mx2[4][j];
local_sum += mx1[i][5] * mx2[5][j];
local_sum += mx1[i][6] * mx2[6][j];
local_sum += mx1[i][7] * mx2[7][j];
mx3[i][j] = local_sum;
}
}MIPS
.data
str: .asciiz "the data of matrix 3:\n"
mx1: .space 512
mx2: .space 512
mx3: .space 512
.text
initial:
daddi r22, r0, mx1
daddi r23, r0, mx2
daddi r21, r0, mx3
input:
daddi r9, r0, 64
daddi r8, r0, 0
loop1:
dsll r11, r8, 3
dadd r10, r11, r22
dadd r11, r11, r23
daddi r12, r0, 2
daddi r13, r0, 3
sd r12, 0(r10)
sd r13, 0(r11)
daddi r8, r8, 1
slt r10, r8, r9
bne r10, r0, loop1
daddi r16, r0, 8
daddi r17, r0, 0
loop2:
daddi r18, r0, 0
loop3:
daddi r19, r0, 0
daddi r20, r0, 0
dsll r8, r17, 6
dsll r9, r19, 3
dadd r9, r8, r9
dadd r9, r9, r22
ld r9, 0(r9)
dsll r10, r19, 6
dsll r11, r18, 3
dadd r10, r10, r11
dadd r10, r10, r23
ld r10, 0(r10)
dmul r12, r9, r10
dadd r20, r20, r12
daddi r19, r19, 1
dsll r9, r19, 3
dadd r9, r8, r9
dadd r9, r9, r22
ld r9, 0(r8)
dsll r10, r19, 6
dadd r10, r10, r11
dadd r10, r10, r23
ld r10, 0(r10)
dmul r12, r9, r10
dadd r20, r20, r12
daddi r19, r19, 1
dsll r9, r19, 3
dadd r9, r8, r9
dadd r9, r9, r22
ld r9, 0(r8)
dsll r10, r19, 6
dadd r10, r10, r11
dadd r10, r10, r23
ld r10, 0(r10)
dmul r12, r9, r10
dadd r20, r20, r12
daddi r19, r19, 1
dsll r9, r19, 3
dadd r9, r8, r9
dadd r9, r9, r22
ld r9, 0(r8)
dsll r10, r19, 6
dadd r10, r10, r11
dadd r10, r10, r23
ld r10, 0(r10)
dmul r12, r9, r10
dadd r20, r20, r12
daddi r19, r19, 1
dsll r9, r19, 3
dadd r9, r8, r9
dadd r9, r9, r22
ld r9, 0(r8)
dsll r10, r19, 6
dadd r10, r10, r11
dadd r10, r10, r23
ld r10, 0(r10)
dmul r12, r9, r10
dadd r20, r20, r12
daddi r19, r19, 1
dsll r9, r19, 3
dadd r9, r8, r9
dadd r9, r9, r22
ld r9, 0(r8)
dsll r10, r19, 6
dadd r10, r10, r11
dadd r10, r10, r23
ld r10, 0(r10)
dmul r12, r9, r10
dadd r20, r20, r12
daddi r19, r19, 1
dsll r9, r19, 3
dadd r9, r8, r9
dadd r9, r9, r22
ld r9, 0(r8)
dsll r10, r19, 6
dadd r10, r10, r11
dadd r10, r10, r23
ld r10, 0(r10)
dmul r12, r9, r10
dadd r20, r20, r12
daddi r19, r19, 1
dsll r9, r19, 3
dadd r9, r8, r9
dadd r9, r9, r22
ld r9, 0(r8)
dsll r10, r19, 6
dadd r10, r10, r11
dadd r10, r10, r23
ld r10, 0(r10)
dmul r12, r9, r10
dadd r20, r20, r12
daddi r19, r19, 1
dsll r8, r17, 6
dsll r9, r18, 3
dadd r8, r8, r9
dadd r8, r8, r21
sd r20, 0(r8)
daddi r18, r18, 1
slt r8, r18, r16
bne r8, r0, loop3
daddi r17, r17, 1
slt r8, r17, r16
bne r8, r0, loop2
halt不宜过度使用
循环展开带来的优化, 是以大量冗余的代码为交换的,需要权衡利弊。