6. riscv-mini运行观察
目标
- riscv-mini架构和Chisel设计
- 观察指令执行
内容
编写risc-v汇编,实现两数相减。 程序编译过程,程序仿真过程。
给定C程序(阶乘计算),完成编译仿真,通过波形图做出程序功能的解释。
配置步骤
开发环境的配置,主要涉及RISC-V工具链部分:
b站录屏
git clone https://github.com/ucb-bar/riscv-mini.git
cd riscv-mini
make
make verilator程序编译和运行
1. 编写汇编程序:
将立即数1和2写入到 x6和x7寄存器中, 两数相加,存入到x5寄存器中
.text
.global _start
_start:
li x6, 1
li x7, 2
add x5, x6, x7
exit:
csrw mtohost, 1
j exit
.end在exit的循环: 将1写入到mtohost(一个csr寄存器)
作用: 通知仿真器结束仿真(类似于 X86汇编 中的 HLT 指令)。
前提: 构建 特权指令集1.7 工具包, 下载参考
2. 编译test.s
riscv32-unknown-elf-gcc -nostdlib -Ttext=0x200 -o test test.s
# 编译完成之后,得到elf文件。
riscv32-unknown-elf-readelf -h test
# 查看系统架构, 入口地址
# 还可以反汇编
riscv32-unknown-elf-objdump -S test输出内容
> riscv32-unknown-elf-readelf -h test
ELF Header:
Magic: 7f 45 4c 46 01 01 01 00 00 00 00 00 00 00 00 00
Class: ELF32
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: EXEC (Executable file)
Machine: RISC-V
Version: 0x1
Entry point address: 0x200
Start of program headers: 52 (bytes into file)
Start of section headers: 860 (bytes into file)
Flags: 0x0
Size of this header: 52 (bytes)
Size of program headers: 32 (bytes)
Number of program headers: 1
Size of section headers: 40 (bytes)
Number of section headers: 5
Section header string table index: 2> riscv32-unknown-elf-objdump -S test
test: file format elf32-littleriscv
Disassembly of section .text:
00000200 <_start>:
200: 00100313 li t1,1
204: 00200393 li t2,2
208: 007302b3 add t0,t1,t2
0000020c <exit>:
20c: 7800d073 csrwi mtohost,1
210: ffdff06f j 20c <exit>提示
在 riscv-mini 上进行仿真,需要将 elf 转换为特定格式的 hex 文件。
- 工具:elf2hex
- 需求:转换为 宽度为16字节的hex文件 。
Usage: elf2hex <width> <depth> <elf_file>
elf2hex 16 4096 test > test.hex
./VTile ./test.hex test.vcd
# 正常情况下:输出
Enabling waves...
Starting simulation!
Simulation completed at time 56 (cycle 5)
Finishing simulation!C程序的编译和运行
1. 编写factorial.c
递归计算一个数的阶乘
int factorial(int num);
void exit();
void main(){
int ans = factorial(10);
exit();
}
int factorial(int num){
if(num <= 1) return 1;
else return num * factorial(num - 1);
}
void exit(){
while(1)
__asm__ __volatile__("csrw mtohost, 1");
}factorial.elf: file format elf32-littleriscv
Disassembly of section .text:
00000200 <main>:
200: fe010113 addi sp,sp,-32
204: 00112e23 sw ra,28(sp)
208: 00812c23 sw s0,24(sp)
20c: 02010413 addi s0,sp,32
210: 00a00513 li a0,10
214: 00c000ef jal 220 <factorial>
218: fea42623 sw a0,-20(s0)
21c: 064000ef jal 280 <exit>
00000220 <factorial>:
220: fe010113 addi sp,sp,-32
224: 00112e23 sw ra,28(sp)
228: 00812c23 sw s0,24(sp)
22c: 02010413 addi s0,sp,32
230: fea42623 sw a0,-20(s0)
234: fec42703 lw a4,-20(s0)
238: 00100793 li a5,1
23c: 00e7c663 blt a5,a4,248 <factorial+0x28>
240: 00100793 li a5,1
244: 0280006f j 26c <factorial+0x4c>
248: fec42783 lw a5,-20(s0)
24c: fff78793 addi a5,a5,-1
250: 00078513 mv a0,a5
254: fcdff0ef jal 220 <factorial>
258: 00050793 mv a5,a0
25c: fec42583 lw a1,-20(s0)
260: 00078513 mv a0,a5
264: 030000ef jal 294 <__mulsi3>
268: 00050793 mv a5,a0
26c: 00078513 mv a0,a5
270: 01c12083 lw ra,28(sp)
274: 01812403 lw s0,24(sp)
278: 02010113 addi sp,sp,32
27c: 00008067 ret
00000280 <exit>:
280: ff010113 addi sp,sp,-16
284: 00812623 sw s0,12(sp)
288: 01010413 addi s0,sp,16
28c: 7800d073 csrwi mtohost,1
290: ffdff06f j 28c <exit+0xc>
00000294 <__mulsi3>:
294: 00050613 mv a2,a0
298: 00000513 li a0,0
29c: 0015f693 andi a3,a1,1
2a0: 00068463 beqz a3,2a8 <__mulsi3+0x14>
2a4: 00c50533 add a0,a0,a2
2a8: 0015d593 srli a1,a1,0x1
2ac: 00161613 slli a2,a2,0x1
2b0: fe0596e3 bnez a1,29c <__mulsi3+0x8>
2b4: 00008067 ret2. 编译
riscv32-unknown-elf-gcc -nostdlib -Ttext=0x200 -march=RV32I -o factorial.elf factorial.c
> 会得到Warning, 不影响后续的实验步骤参数解释
-nostdlib: 不链接标准库-Ttext=0x200: 指定text节的地址为0x200-march=RV32I: 由于riscv-mini的RV32I指令集没有乘法指令, 指定march之后,编译器会自动将乘法指令替换为以移位和加法运算完成的乘法运算
elf2hex 16 4096 factorial.elf > factorial.hex
./VTile ./factorial.hex factorial.vcd
# 正常情况下打印:
Enabling waves...
Starting simulation!
Simulation completed at time 1376 (cycle 137)
Finishing simulation!波形观察, 探索指令执行过程
波形观察
借助gtkwave工具,我们可以通过波形图,观察CPU中各个引脚或者寄存器数值的变化情况,跟踪指令在CPU中的执行过程。
1. 取指阶段
素材: 由test.s 生成的vcd文件
riscv32-unknown-elf-objdump -S test
test: file format elf32-littleriscv
Disassembly of section .text:
00000200 <_start>:
200: 00100313 li t1,1
204: 00200393 li t2,2
208: 007302b3 add t0,t1,t2
0000020c <exit>:
20c: 7800d073 csrwi mtohost,1
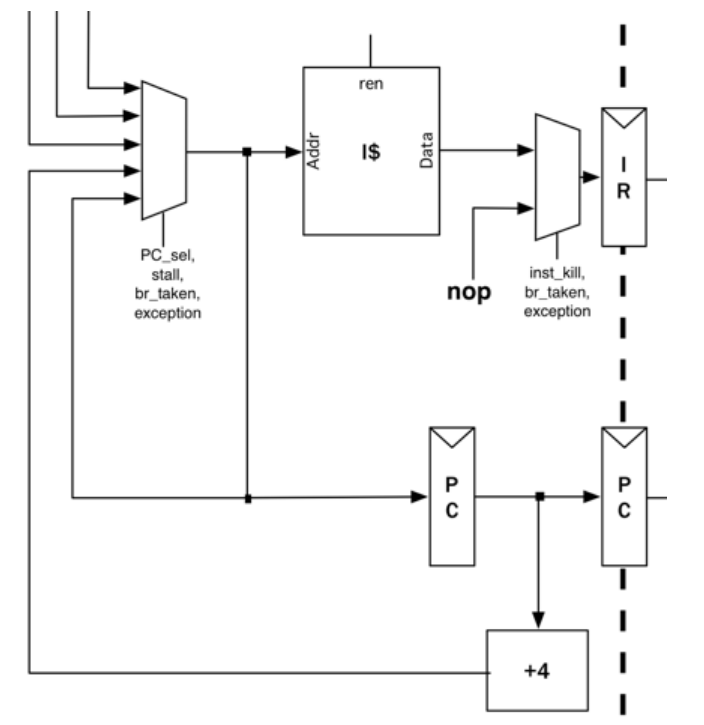
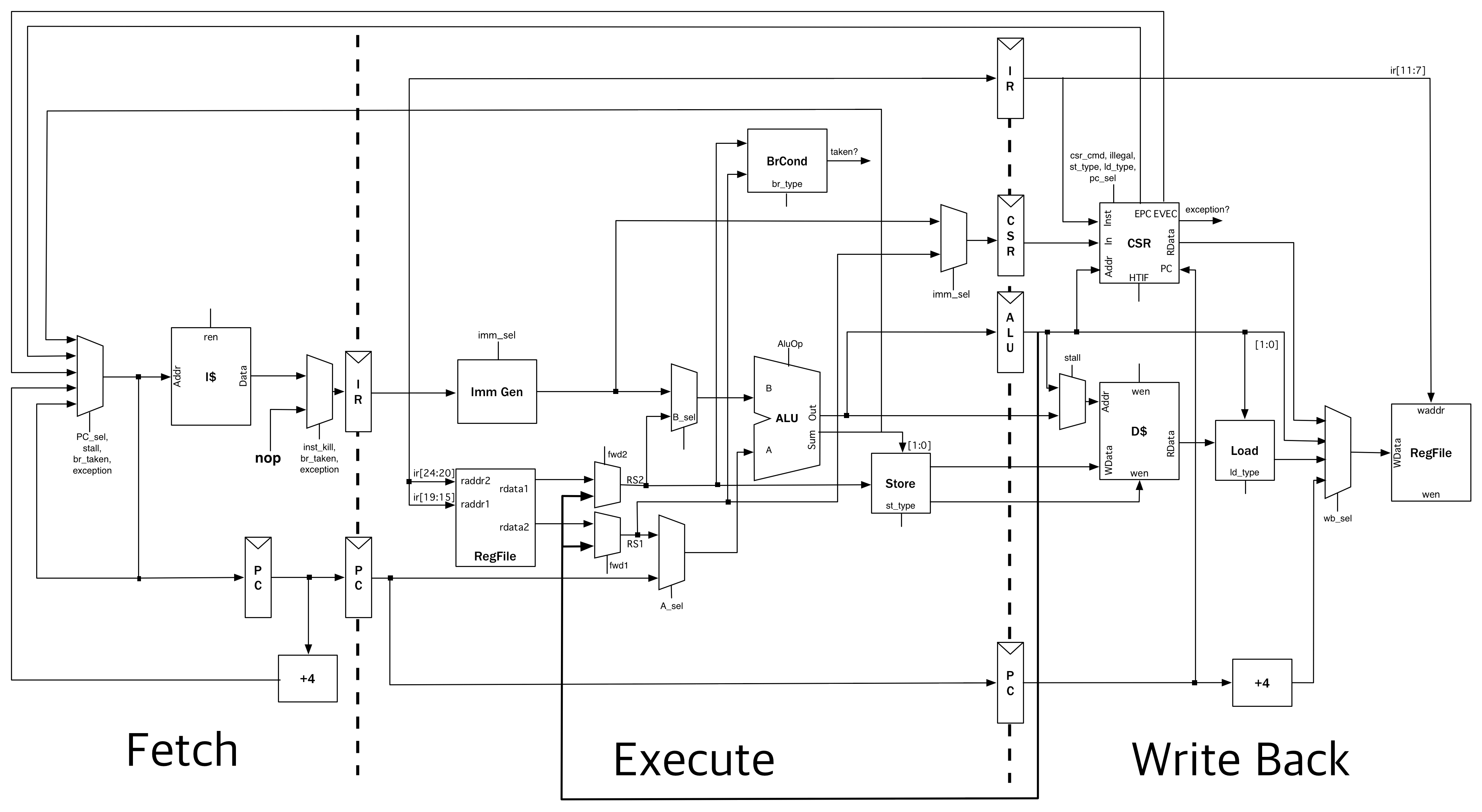
210: ffdff06f j 20c <exit>前置知识
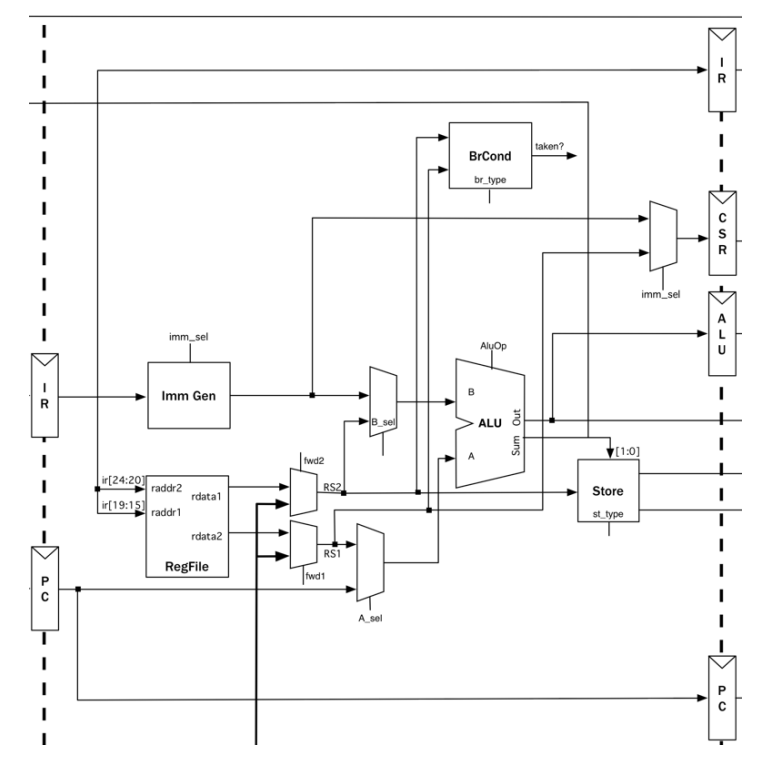
riscv-mini采用三级流水线,
数据通路如图
- 取指:根据 PC值 取出将要执行的指令。
- 通过多路选择器Mux, 选择将要执行的下一条指令地址,
- 随后获取对应地址中的指令,将读取到的指令放入到 Fetch/Execute流水线寄存器 中
当流水线发生分支与异常等情况, 可能需要用空指令产生一个停顿。
取指阶段对应的Chisel代码
next_pc多路选择器,根据控制信号选择下一条指令的地址。
详细过程描述:
- 当流水线开始,PC寄存器 获取
next_pc输出的地址 - 从
icache中读取对应地址的指令, 在没有气泡的情况下,读取到的PC和指令将分别保存到流水线寄存器fe_reg.pc与fe_reg.inst。
/** **** Fetch *****/
val started = RegNext(reset.asBool)
val stall = !io.icache.resp.valid || !io.dcache.resp.valid
val pc = RegInit(Const.PC_START.U(conf.xlen.W) - 4.U(conf.xlen.W))
// Next Program Counter
val next_pc = MuxCase(
pc + 4.U,
IndexedSeq(
stall -> pc,
csr.io.expt -> csr.io.evec,
(io.ctrl.pc_sel === PC_EPC) -> csr.io.epc,
((io.ctrl.pc_sel === PC_ALU) || (brCond.io.taken)) -> (alu.io.sum >> 1.U << 1.U),
(io.ctrl.pc_sel === PC_0) -> pc
)
)
val inst =
Mux(started || io.ctrl.inst_kill || brCond.io.taken || csr.io.expt, Instructions.NOP, io.icache.resp.bits.data)
pc := next_pc
io.icache.req.bits.addr := next_pc
io.icache.req.bits.data := 0.U
io.icache.req.bits.mask := 0.U
io.icache.req.valid := !stall
io.icache.abort := false.B
// Pipelining
when(!stall) {
fe_reg.pc := pc
fe_reg.inst := inst
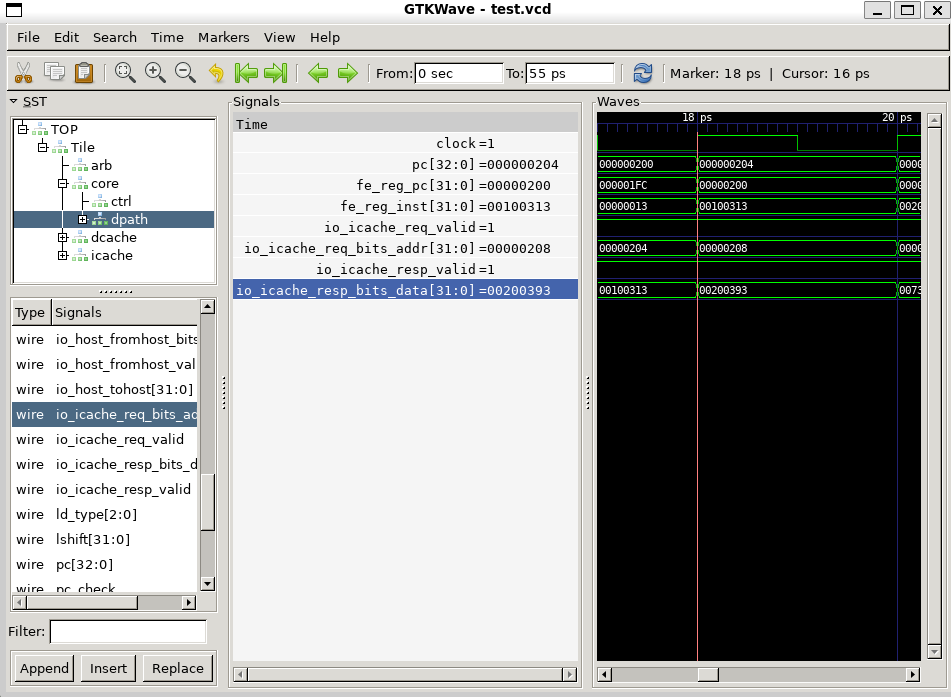
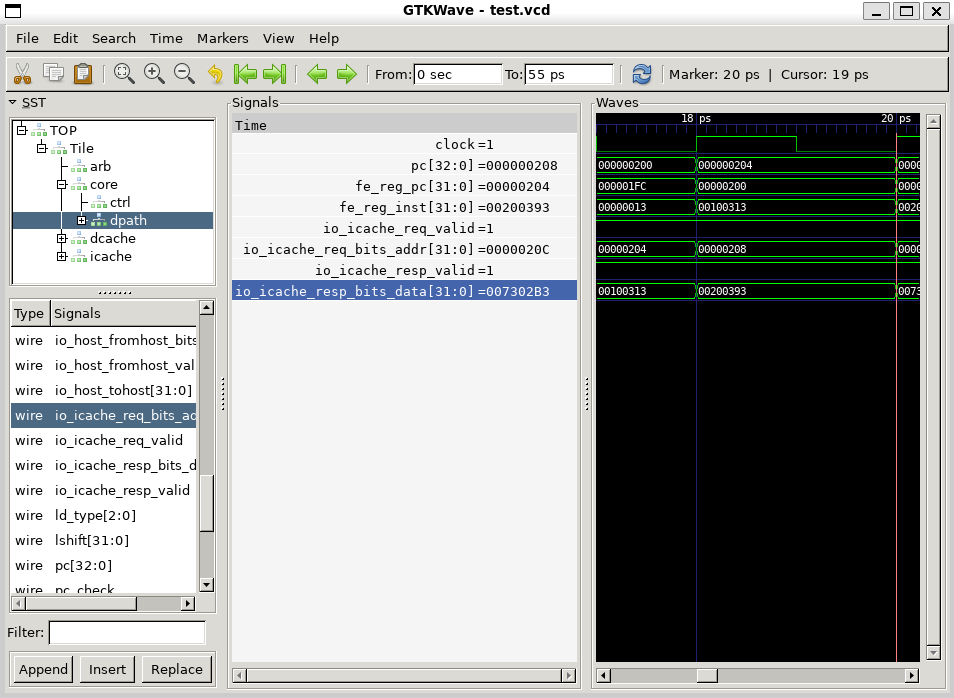
}使用GTKWave打开vcd,验证引脚变量的数值
不妨以第二条指令为观察对象 (快照)- li t2, 2
li指令是一条伪指令,用于加载立即数。 编译器会根据立即数的大小, 将其转化为一条或两条等价功能的指令来执行。
在这里li t2,2与addi x7,x0,2等价。
- 从波形图中观察验证:
io_icache_req_addr=next_pc
若cache命中,直接在下一时钟周期取得对应指令
如果不命中,产生停顿,直到从内存中读取完成
- cache命中,根据 PC值 从 cache 读取得到指令
0x00200393(即li t2,2)
且在下一个周期写入到流水线寄存器中
fe_reg_inst。
该指令所在内存地址:
波形图验证
2. 执行阶段
基本任务:
- 指令译码
- 准备操作数(从regfile中读取或产生立即数)
- 指令执行以及访存(访存指令)。
处理过程:
- 指令译码, 通过立即数生成单元, 以及访问寄存器文件获得操作数,用来作为ALU的输入。
- ALU具体的输入由多个 多路选择器 做出选择,
可能来自寄存器、或立即数、或PC、或 forwaring (来自EXE/WB流水线寄存器中的数值)。
- 分支指令由BrCond模块进行判断,若需要分支,则下一条指令的PC地址为分支指令的目标地址。
对应的Chisel代码
- 将指令传给控制单元, 以读取相应的控制信号
- 将相应寄存器号传给寄存器文件, 以读取需要的操作数
- 指令传给立即数生成单元, 以读取需要的立即数。
- 对ALU的输入数据做出选择
- 判断该指令是否产生分支
- 对于lw和sw指令,使用计算出的地址访问数据cache进行访存操作。
- 正常情况,产生的数据放入到EXE/WB流水线寄存器。
/** **** Execute *****/
io.ctrl.inst := fe_reg.inst
// regFile read
val rd_addr = fe_reg.inst(11, 7)
val rs1_addr = fe_reg.inst(19, 15)
val rs2_addr = fe_reg.inst(24, 20)
regFile.io.raddr1 := rs1_addr
regFile.io.raddr2 := rs2_addr
// gen immdeates
immGen.io.inst := fe_reg.inst
immGen.io.sel := io.ctrl.imm_sel
// bypass
val wb_rd_addr = ew_reg.inst(11, 7)
val rs1hazard = wb_en && rs1_addr.orR && (rs1_addr === wb_rd_addr)
val rs2hazard = wb_en && rs2_addr.orR && (rs2_addr === wb_rd_addr)
val rs1 = Mux(wb_sel === WB_ALU && rs1hazard, ew_reg.alu, regFile.io.rdata1)
val rs2 = Mux(wb_sel === WB_ALU && rs2hazard, ew_reg.alu, regFile.io.rdata2)
// ALU operations
alu.io.A := Mux(io.ctrl.A_sel === A_RS1, rs1, fe_reg.pc)
alu.io.B := Mux(io.ctrl.B_sel === B_RS2, rs2, immGen.io.out)
alu.io.alu_op := io.ctrl.alu_op
// Branch condition calc
brCond.io.rs1 := rs1
brCond.io.rs2 := rs2
brCond.io.br_type := io.ctrl.br_type
// D$ access
val daddr = Mux(stall, ew_reg.alu, alu.io.sum) >> 2.U << 2.U
val woffset = (alu.io.sum(1) << 4.U).asUInt | (alu.io.sum(0) << 3.U).asUInt
io.dcache.req.valid := !stall && (io.ctrl.st_type.orR || io.ctrl.ld_type.orR)
io.dcache.req.bits.addr := daddr
io.dcache.req.bits.data := rs2 << woffset
io.dcache.req.bits.mask := MuxLookup(
Mux(stall, st_type, io.ctrl.st_type),
"b0000".U,
Seq(ST_SW -> "b1111".U, ST_SH -> ("b11".U << alu.io.sum(1, 0)), ST_SB -> ("b1".U << alu.io.sum(1, 0)))
)
// Pipelining
when(reset.asBool || !stall && csr.io.expt) {
st_type := 0.U
ld_type := 0.U
wb_en := false.B
csr_cmd := 0.U
illegal := false.B
pc_check := false.B
}.elsewhen(!stall && !csr.io.expt) {
ew_reg.pc := fe_reg.pc
ew_reg.inst := fe_reg.inst
ew_reg.alu := alu.io.out
ew_reg.csr_in := Mux(io.ctrl.imm_sel === IMM_Z, immGen.io.out, rs1)
st_type := io.ctrl.st_type
ld_type := io.ctrl.ld_type
wb_sel := io.ctrl.wb_sel
wb_en := io.ctrl.wb_en
csr_cmd := io.ctrl.csr_cmd
illegal := io.ctrl.illegal
pc_check := io.ctrl.pc_sel === PC_ALU
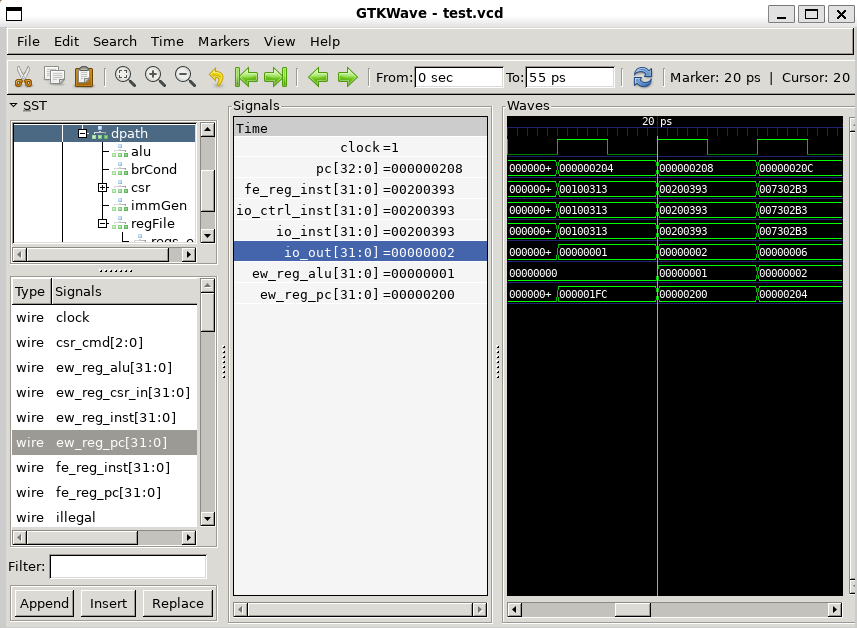
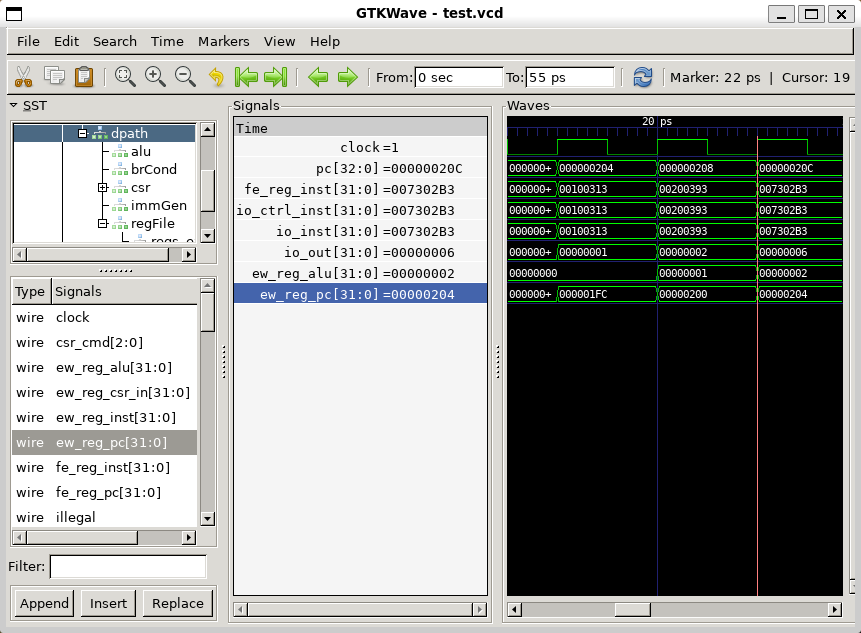
}仍然以第二条指令为观察对象 (快照)- li t2, 2
li是伪指令,等价于指令
addi x7,x0,2
操作数分别来自立即数x0寄存器,立即数生成单元。
在波形图中观察验证:
- 来自取指阶段的指令(fe_reg_inst)传递给立即数生成单元(immGen)、控制单元(ctrl)。
- immGen给出立即数0x02,寄存器文件给出x0的数值。
- ALU中以x0的值以及0x02作为输入,相加得到结果0x02
- 在下个时钟周期,流水线寄存器ew_reg_alu的值为ALU的结果0x02。
该指令所在内存地址:
波形图
3. 写回阶段
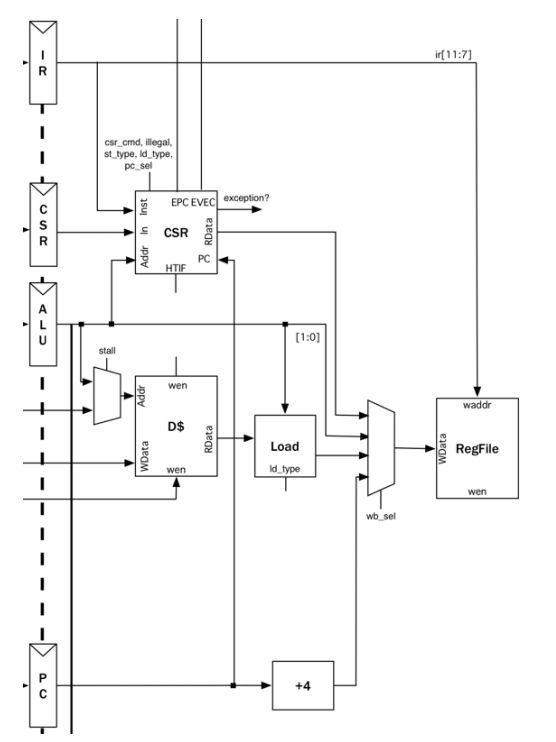
基本任务: 将在执行阶段产生的结果回写到寄存器中。
根据指令类型, 选择对应的结果写入,
对于LW指令,需要访问内存获取数据 dcache 回写CSR寄存器 回写寄存器文件
对应的Chisel代码
处理过程:
- 从
dcache读取数据 - 根据指令类型提取需要的位。
- 同时CSR的访问也在该阶段进行。
- 根据控制信号,将需要的数据写回到寄存器文件当中。
// Load
val loffset = (ew_reg.alu(1) << 4.U).asUInt | (ew_reg.alu(0) << 3.U).asUInt
val lshift = io.dcache.resp.bits.data >> loffset
val load = MuxLookup(
ld_type,
io.dcache.resp.bits.data.zext,
Seq(
LD_LH -> lshift(15, 0).asSInt,
LD_LB -> lshift(7, 0).asSInt,
LD_LHU -> lshift(15, 0).zext,
LD_LBU -> lshift(7, 0).zext
)
)
// CSR access
csr.io.stall := stall
csr.io.in := ew_reg.csr_in
csr.io.cmd := csr_cmd
csr.io.inst := ew_reg.inst
csr.io.pc := ew_reg.pc
csr.io.addr := ew_reg.alu
csr.io.illegal := illegal
csr.io.pc_check := pc_check
csr.io.ld_type := ld_type
csr.io.st_type := st_type
io.host <> csr.io.host
// Regfile Write
val regWrite =
MuxLookup(
wb_sel,
ew_reg.alu.zext,
Seq(WB_MEM -> load, WB_PC4 -> (ew_reg.pc + 4.U).zext, WB_CSR -> csr.io.out.zext)
).asUInt
regFile.io.wen := wb_en && !stall && !csr.io.expt
regFile.io.waddr := wb_rd_addr
regFile.io.wdata := regWrite
// Abort store when there's an excpetion
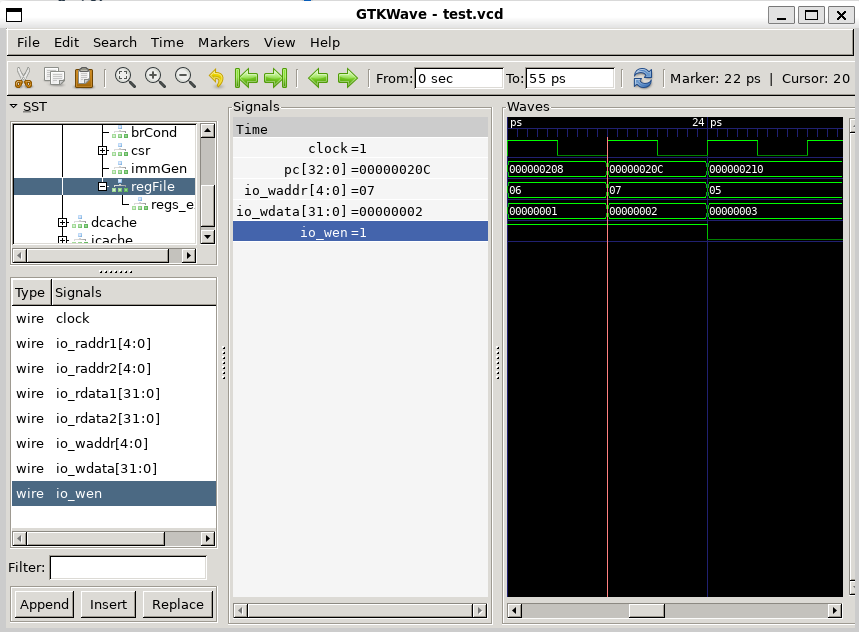
io.dcache.abort := csr.io.expt对于li t2, 2(即addi x7,x0,2)指令, 在写回阶段将0x02写入到x7寄存器当中。
- 从波形图中观察验证
- 寄存器文件的写地址信号为07,且写信号有效位为1,
- 在下个时钟周期, 0x02将被成功写入到x7寄存器当中。
波形图
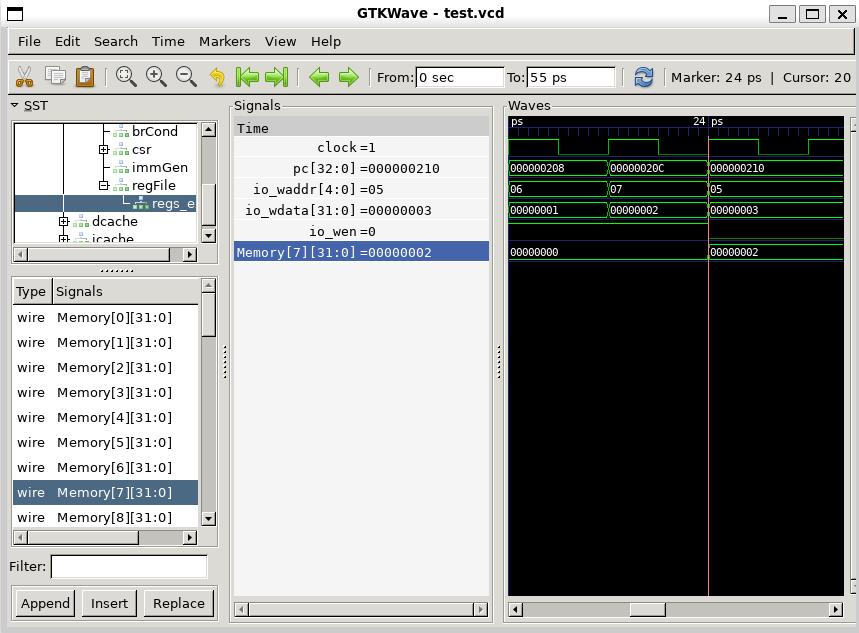
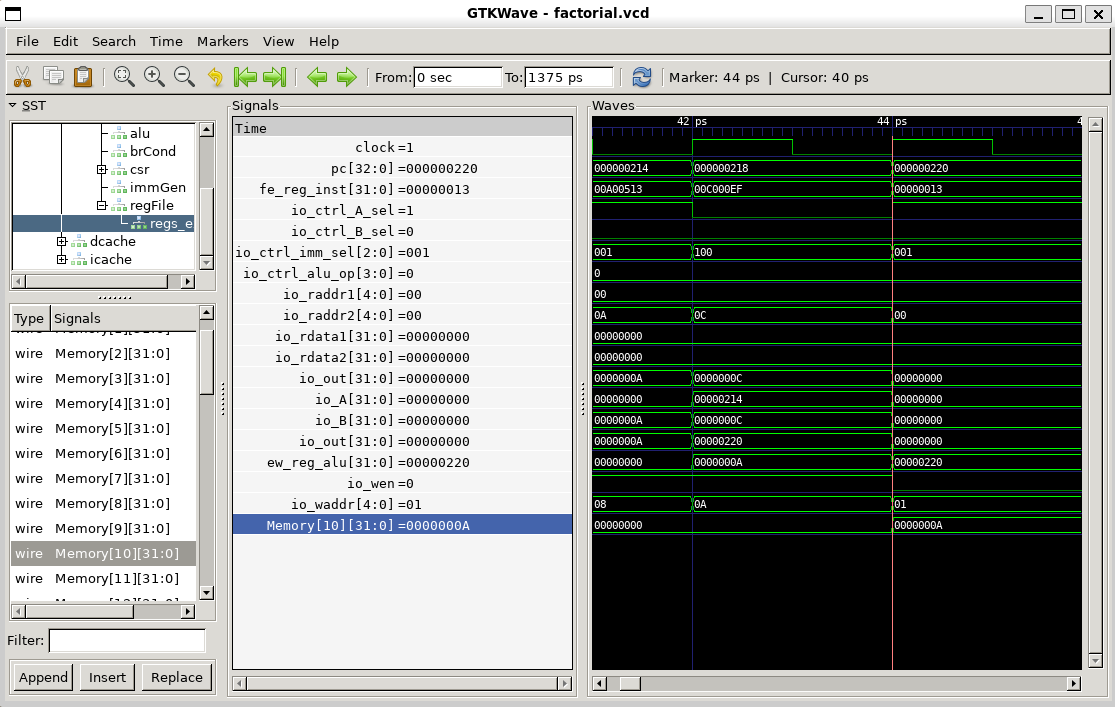
观察factorial的传参
分析factorial(10) 的过程
观察汇编代码
- 首先addi指令偏移了栈指针,申请了32字节的栈空间,
- 两条sw指令将ra和s0的值保存在栈空间的指定位置,
其中ra是用于保存函数返回地址的,s0则是存放需要保存的数据。
将这两个寄存器值保存到堆栈即是在完成我们常说的在函数调用前保存现场的操作。
- 我们要观察的factorial()函数第一次调用时参数10的传入是在哪条指令进行的?
在li a0,10
在跳转到factorial函数前将参数10传到a0(x10)寄存器中,
按照RISC-V的规范约定,函数的参数传递可以使用寄存器a0~a7,这里factoria函数只有一个参数, 所以使用a0进行参数传递。
00000200 <main>:
200: fe010113 addi sp,sp,-32
204: 00112e23 sw ra,28(sp)
208: 00812c23 sw s0,24(sp)
20c: 02010413 addi s0,sp,32
210: 00a00513 li a0,10
214: 00c000ef jal 220 <factorial>
218: fea42623 sw a0,-20(s0)
21c: 064000ef jal 280 <exit>
00000220 <factorial>:
220: fe010113 addi sp,sp,-32
224: 00112e23 sw ra,28(sp)
228: 00812c23 sw s0,24(sp)
22c: 02010413 addi s0,sp,32
230: fea42623 sw a0,-20(s0)
234: fec42703 lw a4,-20(s0)
238: 00100793 li a5,1
23c: 00e7c663 blt a5,a4,248 <factorial+0x28>
240: 00100793 li a5,1
244: 0280006f j 26c <factorial+0x4c>
248: fec42783 lw a5,-20(s0)
24c: fff78793 addi a5,a5,-1
250: 00078513 mv a0,a5
254: fcdff0ef jal 220 <factorial>
258: 00050793 mv a5,a0
25c: fec42583 lw a1,-20(s0)
260: 00078513 mv a0,a5
264: 030000ef jal 294 <__mulsi3>
268: 00050793 mv a5,a0
26c: 00078513 mv a0,a5
270: 01c12083 lw ra,28(sp)
274: 01812403 lw s0,24(sp)
278: 02010113 addi sp,sp,32
27c: 00008067 ret
00000280 <exit>:
280: ff010113 addi sp,sp,-16
284: 00812623 sw s0,12(sp)
288: 01010413 addi s0,sp,16
28c: 7800d073 csrwi mtohost,1
290: ffdff06f j 28c <exit+0xc>
00000294 <__mulsi3>:
294: 00050613 mv a2,a0
298: 00000513 li a0,0
29c: 0015f693 andi a3,a1,1
2a0: 00068463 beqz a3,2a8 <__mulsi3+0x14>
2a4: 00c50533 add a0,a0,a2
2a8: 0015d593 srli a1,a1,0x1
2ac: 00161613 slli a2,a2,0x1
2b0: fe0596e3 bnez a1,29c <__mulsi3+0x8>
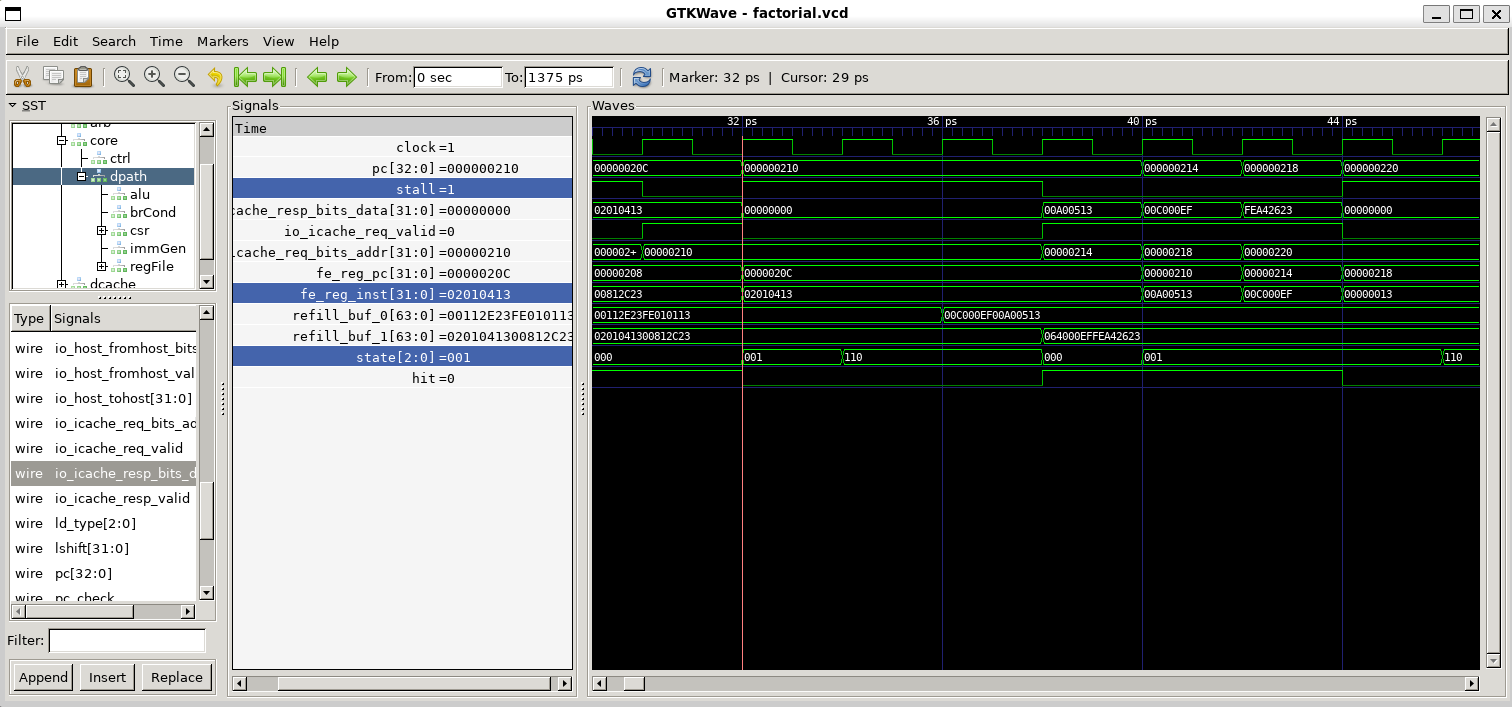
2b4: 00008067 ret观察指令缓存机制
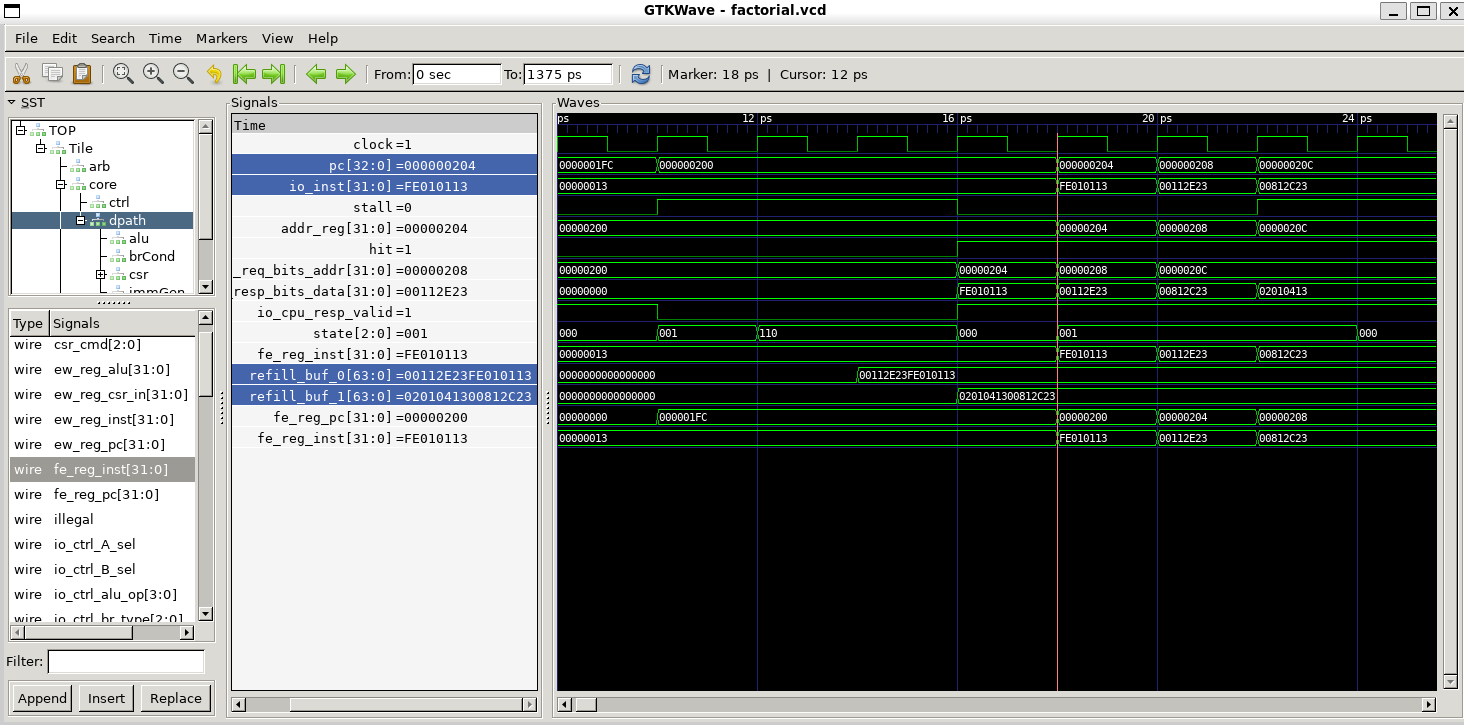
从波形图中观察验证:
icache的req.addr端口与next_pc相等,
当next_pc命中缓存,下个周期next_pc的值装入PC的同时,就能从icache中取出对应的指令。
否则,next_pc的值装入PC之后,并不能立即读到指令
当cache缺失,则需要访问内存,这个过程称为refill
refill_buf_0, 和refill_buf_1是指令缓存的位置。- 写缓存:停顿信号保持三个周期 (这期间注意cache模块的状态跳转)
状态变化 sReadCache x 1 clock -> sRefill x 2 clock
- 缓存的不命中:
流水线停顿信号保持四个周期,访问内存,用于后续刷新缓存
之后的一个时钟周期短暂恢复流水线,更新icache的请求地址
重新停顿,同时fe_reg_inst更新,启动上条指令的执行阶段。
在停顿期间进行写缓存, 刷新缓存
波形图验证
观察控制信号的变化
控制单元经过指令译码之后得到的部分控制信号,
io_ctrl_a_sel和io_ctrl_b_sel表示ALU的操作数来源,io_ctrl_imm_sel表示立即数的格式io_ctrl_alu_op表示ALU需要进行的操作。
上述信号的取值意义
建议查看源码,此处罗列关键部分
// A_sel
val A_XXX = 0.U(1.W)
val A_PC = 0.U(1.W)
val A_RS1 = 1.U(1.W)
// B_sel
val B_XXX = 0.U(1.W)
val B_IMM = 0.U(1.W)
val B_RS2 = 1.U(1.W)
// imm_sel
val IMM_X = 0.U(3.W)
val IMM_I = 1.U(3.W)
val IMM_S = 2.U(3.W)
val IMM_U = 3.U(3.W)
val IMM_J = 4.U(3.W)
val IMM_B = 5.U(3.W)
val IMM_Z = 6.U(3.W)object Alu {
val ALU_ADD = 0.U(4.W)
val ALU_SUB = 1.U(4.W)
val ALU_AND = 2.U(4.W)
val ALU_OR = 3.U(4.W)
val ALU_XOR = 4.U(4.W)
val ALU_SLT = 5.U(4.W)
val ALU_SLL = 6.U(4.W)
val ALU_SLTU = 7.U(4.W)
val ALU_SRL = 8.U(4.W)
val ALU_SRA = 9.U(4.W)
val ALU_COPY_A = 10.U(4.W)
val ALU_COPY_B = 11.U(4.W)
val ALU_XXX = 15.U(4.W)
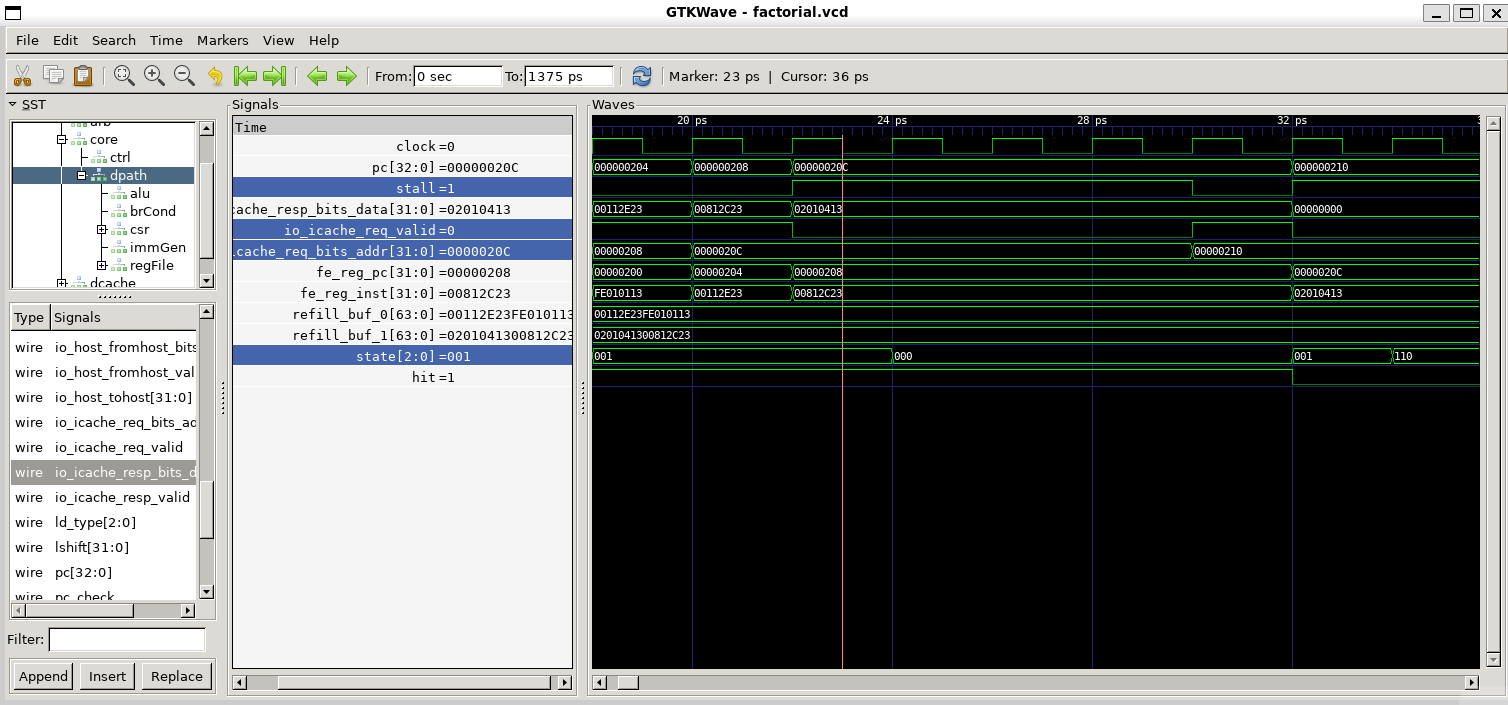
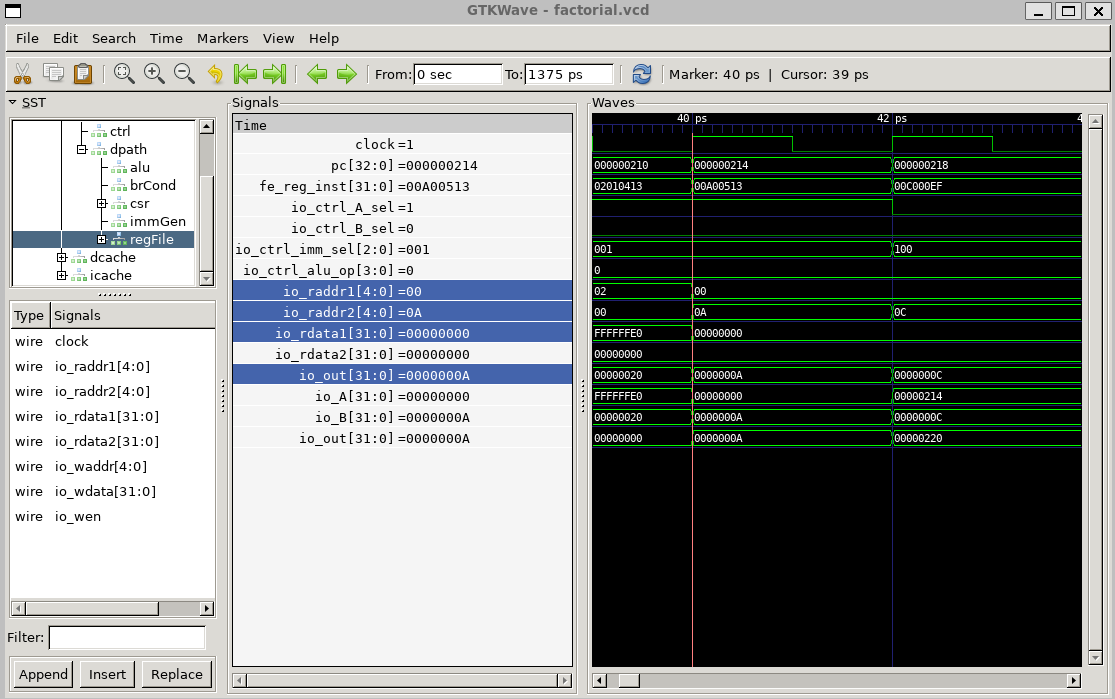
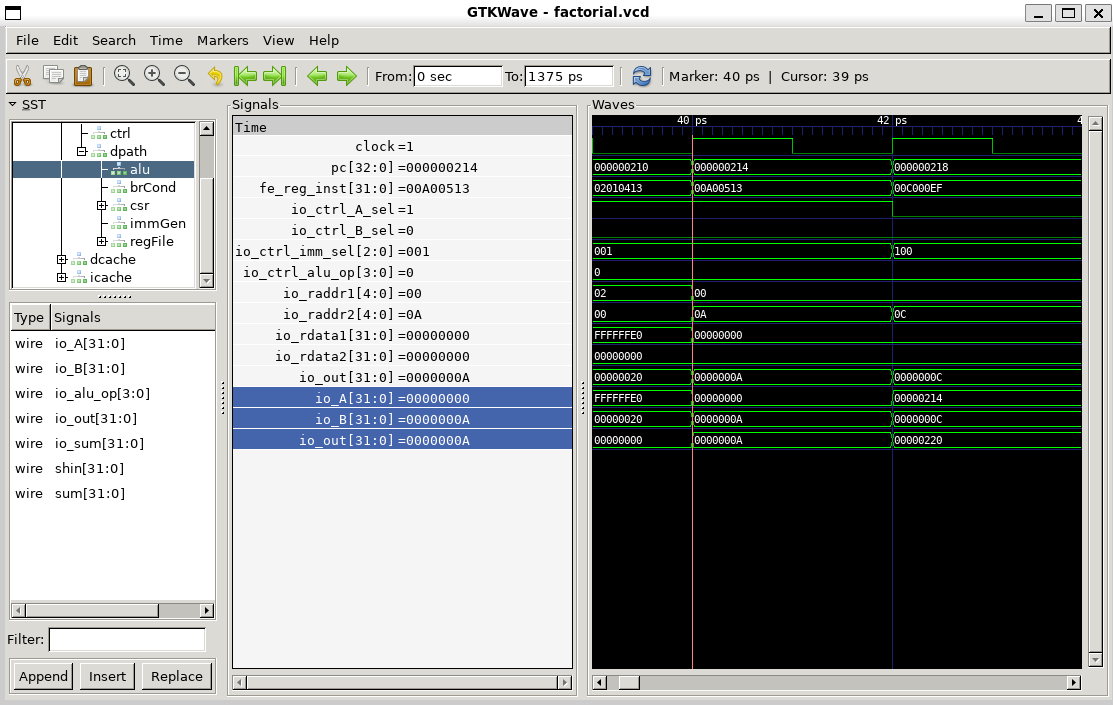
}重点关注指令li a0,10, 地址0x210, 十六进制0x00a00513
伪指令,对应
add a0, x0, 10从波形图中观察验证:
- 在取得
0x00a00513指令输入后,经过译码,这些控制信号的输出分别为:
| 控制信号 | 输出 |
|---|---|
io_ctrl_a_sel | 1,对应 A_RS1 |
io_ctrl_b_sel | 0,对应 B_IMM |
io_ctrl_imm_sel | 001, 对应IMM_I |
io_ctrl_alu_op | 0000,对应ALU_ADD |
- 观察寄存器文件和立即数生成单元
- 观察ALU单元
- 验证寄存器最终结果
波形图验证

FPGA原型验证
1. MMIO
MMIO 是CPU与外设交互的一种方法,通过将外设相关的寄存器映射到处理器的内存地址中来访问。当CPU需要访问外设时只需要通过访存指令访问外设对应的寄存器即可,不需要为外设添加额外的指令。
2. riscv-mini的调整
项目本身没有外设以及物理的内存模块,而是通过软件访问的内存在仿真环境中运行程序。
调整riscv-mini,为其添加外设以及内存模块,让其能在FPGA上运行程序。 在外设部分为其添加:
- 串口
- LED控制器
- 物理内存通过FPGA上的 BRAM 实现。
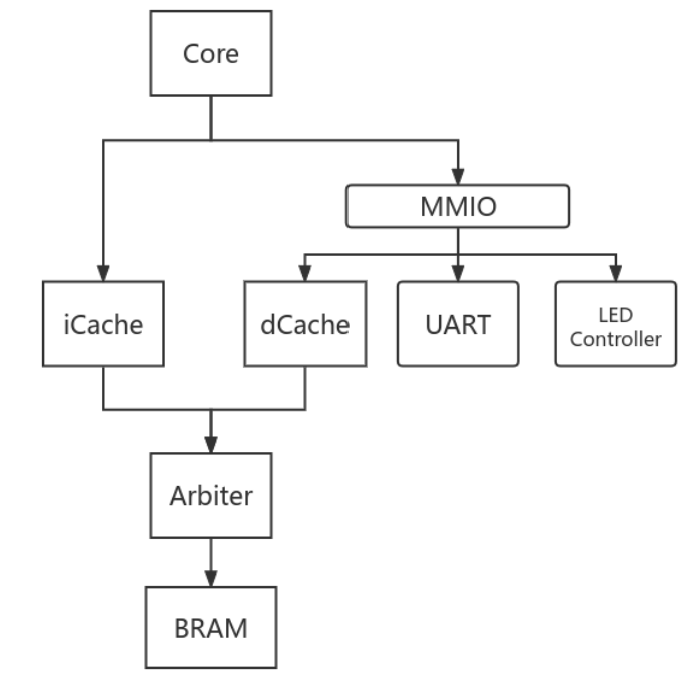
2.1 内存映射
- UART共四个端口,分别用于表示IO的data和valid。
- LED共一个端口 映射的内存地址:
UART:
read_valid 0x1000_0000
read_data 0x1000_0004
write_valid 0x1000_0008
write_data 0x1000_000cUART模块的波特率设置为57600,采用轮询的方式。
当CPU想要向UART发送数据
首先循环读取write_valid,判断UART是否可写。当true,则将数据写入write_data即可。 当CPU想要读取UART的数据时,步骤相近。
LED控制器,设定通过位模式来表示FPGA板上四个灯的亮灭。
2.2 程序准备
拟定测试UART的回显程序
- 作用是循环从串口中读取数据,将读取到的数据通过串口发送出去。
.text # Define beginning of text section
.global _start # Define entry _start
_start:
li x1,0x10000000 #read valid 0x10000000
li x2,0x10000004 #read data 0x10000004
li x3,0x10000008 #write ready 0x10000008
li x4,0x1000000C #write data 0x1000000C
ECHO_Loop:
CheckReadValid:
lb x5,0(x1)
beq x5,x0,CheckReadValid
lb x6,0(x2) #if valid == 1 read data else loop
CheckWriteReady:
lb x5,0(x3)
beq x5,x0,CheckWriteReady #if rady == 1 write data else loop
sb x6,0(x4)
j ECHO_Loop程序通过工具链最后转换成hex文件,
当使用FPGA上的BRAM时,需要从hex转换成coe格式对内存初始化。
拟定测试LED的控制程序
- 程序功能:根据UART的输入来控制亮灭
- 具体行为:初始化写入1111,代表全亮。随后轮询UART,实时改变LED组的亮灭状态。
.text
.global _start
_start:
li t0,0x10000000 #read valid 0x10000000
li t1,0x10000004 #read data 0x10000004
li t2,0x10010000 #LED state
#init
addi t3,x0,15
sw t3,0(t2)
LOOP:
CheckReadValid:
lb t3,0(t0)
beq t3,x0,CheckReadValid
lb t4,0(t1) #if valid == 1 read data else loop
# change led state
addi t4,t4,-48 #char to int
addi t5,x0,1 #select led
sll t5,t5,t4
sw t5,0(t2)
j LOOP2.3 FPGA综合与实现
- 板子: 采用ARTY A7-35T
- 源文件导入Tile.v文件,使用如下的约束文件,在约束文件中分配引脚。
具体约束
# Clock signal
set_property -dict { PACKAGE_PIN E3 IOSTANDARD LVCMOS33 } [get_ports { clock }]; #IO_L12P_T1_MRCC_35 Sch=gclk[100]
create_clock -add -name sys_clk_pin -period 10.00 -waveform {0 5} [get_ports { clock }];
# Buttons
set_property -dict { PACKAGE_PIN D9 IOSTANDARD LVCMOS33 } [get_ports { reset }]; #IO_L6N_T0_VREF_16 Sch=btn[0]
# USB-UART Interface
set_property -dict { PACKAGE_PIN D10 IOSTANDARD LVCMOS33 } [get_ports { io_txd }]; #IO_L19N_T3_VREF_16 Sch=uart_rxd_out
set_property -dict { PACKAGE_PIN A9 IOSTANDARD LVCMOS33 } [get_ports { io_rxd }]; #IO_L14N_T2_SRCC_16 Sch=uart_txd_in
# LEDs
set_property -dict { PACKAGE_PIN H5 IOSTANDARD LVCMOS33 } [get_ports { io_ledState[0] }]; #IO_L24N_T3_35 Sch=led[4]
set_property -dict { PACKAGE_PIN J5 IOSTANDARD LVCMOS33 } [get_ports { io_ledState[1] }]; #IO_25_35 Sch=led[5]
set_property -dict { PACKAGE_PIN T9 IOSTANDARD LVCMOS33 } [get_ports { io_ledState[2] }]; #IO_L24P_T3_A01_D17_14 Sch=led[6]
set_property -dict { PACKAGE_PIN T10 IOSTANDARD LVCMOS33 } [get_ports { io_ledState[3] }]; #IO_L24N_T3_A00_D16_14 Sch=led[7]在Vivado中实例化BRAM。在IP Catalog中选择Block Memory Generator, 创建BRAM。
设置接口类型为AXI4。
在PortA中设置BRAM的宽度和深度,注意板上的BRAM资源有限。
在other中选择对应的coe文件初始化,取消勾选 Enable Safety Circuit
然后进行综合、实现、生成比特流。
写入FPGA后,通过串口和FPGA通信
期望行为:
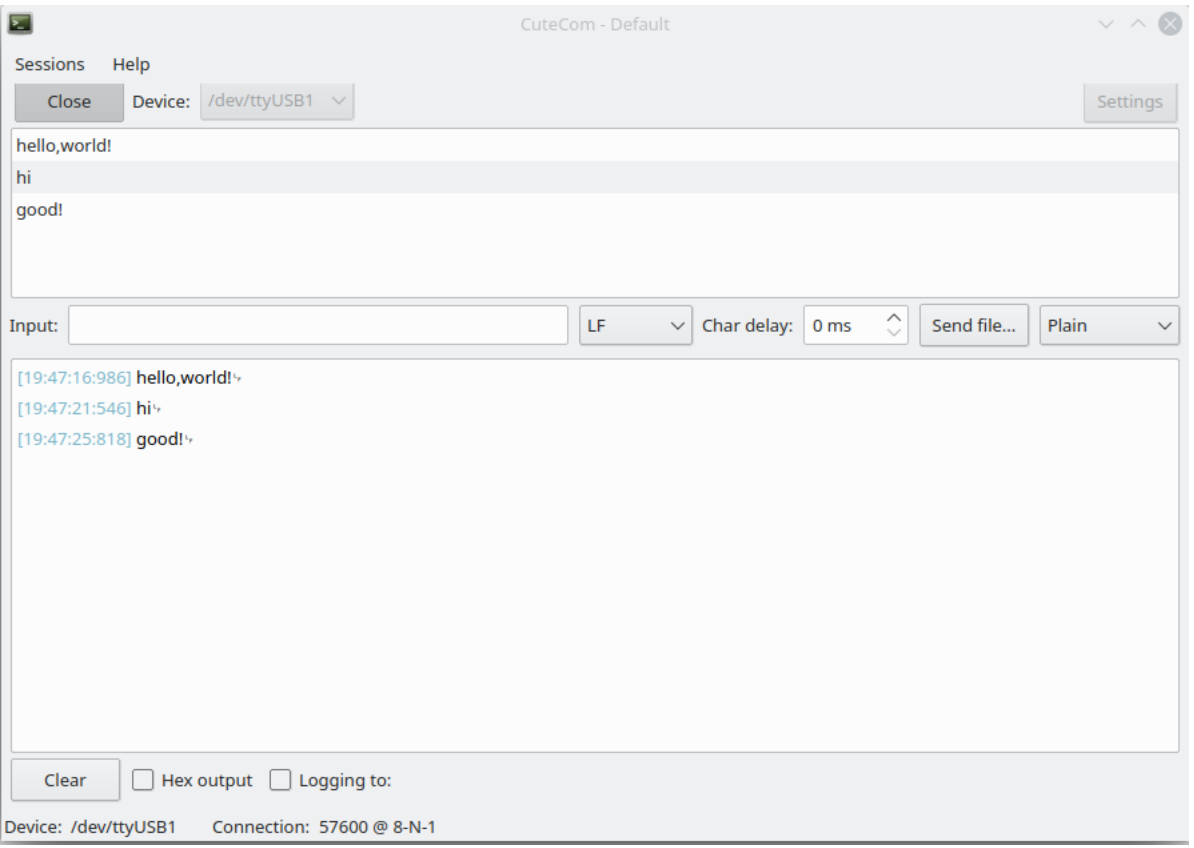
换成blink程序后的期望结果:
- 初始点灯

- 发送数字 (从0算起) : 发送2代表让第三个灯亮
